

IN THIS SITE...

Overview of HES processing
This article offers an overview of the data quality process involved in the production of HES data extracts.
How HES data is extracted
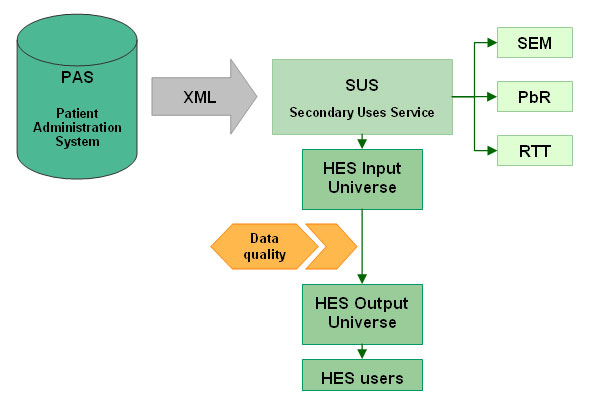 |
The diagram above is a simplified version of how HES is extracted. It can be broken down as follows:
- PAS (Patient Administration System): system used by trusts to submit data to SUS.
- XML: specification used for submitting and validating data to SUS.
- SUS (Secondary Uses Service): a data warehouse used to store information. Extracts are created from this data warehouse for RTT (Referral to Treatment), PbR (Payment by Results), SEM (SUS Extract Mart) and HES.
- HES Input Universe: the raw HES data straight from SUS. This is where the data is cleaned and additional fields are derived.
- HES Output Universe: cleaned data is stored here and can be accessed by HES users.
The HES Data Quality team are responsible for cleaning the data, enabling the HES Output Universe to be created from the HES Input Universe.
Monthly HES extracts: 2008-09 onwards
In previous years extracts were submitted quarterly (provisional data), with an additional extract called annual refresh (published data) at the end of quarter four.
Since April 2008-09 these extracts have been taken from SUS on a monthly basis. Each extract contains data submitted for the year so far, ie Month 1 will only contain the data submitted for April, but Month 6 will contain data submitted from April to September. One of the reasons for this is that additional data may need to be added to an episode from earlier in the year, eg an episode may potentially run for several months or an amendment may need to be made.
You can find details of the current HES submission deadlines on the Submission Deadlines page.
The cleaning process
Within the HES Input Universe, cleaning is broken down into four stages:
1. Provider mapping
During this stage any old or invalid provider codes are changed / merged to new valid provider codes (using reference data based on information from the ODS website).
2. Automatic cleaning
During this stage a pre-defined list of cleaning rules that remove or correct common errors is worked through, including:
- Sex: changing M, m, F, f entries to 0, 1, 2 and so on
- Diagnosis codes: changing the capitalisation on entries, such as k40.3.
- Operation codes: removing excess characters, such as & and -.
The introduction of XML validation is helping to improve data quality from the initial submission stage.
3. Manual cleaning
During this stage:
- Records outside the relevant date range are removed, eg removing November data from the October extract.
- Duplicate records are removed.
- Specific requests from providers to remove data are carried out.
4. Derivation
During this stage the following information is derived:
- PCTs (residence, responsibility and treatment) are derived from the appropriate postcode
- Mentions
- Organisation names from reference data
- Group fields, such as age
- Descriptions, eg procedures and diagnosis
- HES ID, a patient unique ID for each HES data year.
Full details of the cleaning process can be found in the Data Cleaning section.
Feedback
An important part of the cleaning process is feedback. The Data Quality team liaise with providers on a range of subjects, including:
- mapping data to specific providers
- missing data
- duplicate data
- queries about specific sections of data, such as maternity data.
They also:
- encourage providers to clean (correct) their data before the next extract is taken, where possible
- offer advice where issues occur in the submission process
- recommend to providers, where necessary, that they request deletions of data from within SUS itself.
Understanding the data
The HES data dictionaries, cleaning rules files and the Data Quality Dashboard are good sources of information about HES fields and data quality.
Summary
Aims of the Data Quality team
The HES Data Quality team aims to:
- produce cleaned data for use by providers and HES users
- encourage providers to understand that the data is their responsibility and that bad data has consequences for them
- provide guidance, feedback and assistance to ensure data quality begins at the source.
Further information
If you have any questions about HES data quality or anything covered in this article please contact the HES Data Quality team ([email protected]).